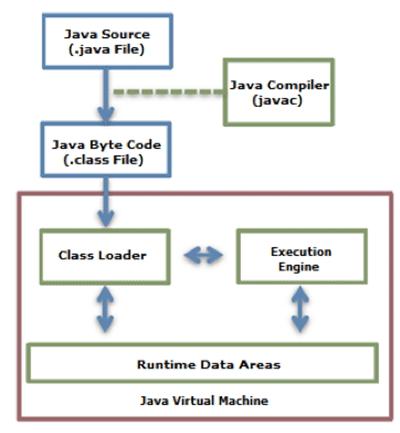
Java代码编译和执行的整个过程包含了以下三个重要的机制:
Java源码编译机制
类加载机制
类执行机制
整个流程如下图:
一、Java源码编译
Java代码编译是由Java源码编译器(Java Compiler,javac)来完成,流程图如下所示:
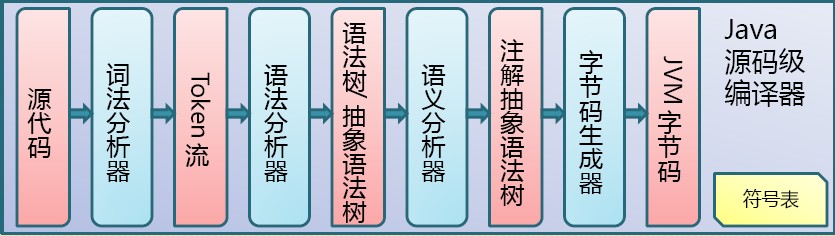
Java 源码编译由以下三个过程组成:
1. 分析和输入到符号表
2. 注解处理
3. 语义分析和生成class文件
流程图如下所示:

最后生成的class文件由以下部分组成:
结构信息:包括class文件格式版本号及各部分的数量与大小的信息
元数据:对应于Java源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池
方法信息:对应Java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息。
二、类加载机制
1、类加载器(ClassLoader)
把类加载阶段的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作交给虚拟机之外的类加载器来完成。这样的好处在于,我们可以自行实现类加载器来加载其他格式的类,只要是二进制字节流就行,这就大大增强了加载器灵活性。
参见:《深入JVM类加载机制》http://blog.csdn.net/dd864140130/article/details/49817357
装载.class文件classloader 有两种装载class的方式 (时机):
隐式:运行过程中,碰到new方式生成对象时,隐式调用classLoader到JVM
显式:通过class.forName()动态加载
2、双亲委派模式
Java提供了动态的装载特性;它会在运行时的第一次引用到一个class的时候对它进行装载和链接,而不是在编译期进行。JVM的类装载器负责动态装载。Java类装载器有如下几个特点:
层级结构:Java里的类装载器被组织成了有父子关系的层级结构。Bootstrap类装载器是所有装载器的父亲。
代理模式:基于层级结构,类的装载可以在装载器之间进行代理。当装载器装载一个类时,首先会检查它是否在父装载器中进行装载了。如果上层的装载器已经装载了这个类,这个类会被直接使用。反之,类装载器会请求装载这个类。
可见性限制:一个子装载器可以查找父装载器中的类,但是一个父装载器不能查找子装载器里的类。
不允许卸载:类装载器可以装载一个类但是不可以卸载它,不过可以删除当前的类装载器,然后创建一个新的类装载器。
每个类装载器都有一个自己的命名空间用来保存已装载的类。当一个类装载器装载一个类时,它会通过保存在命名空间里的类全局限定名(Fully Qualified Class Name)进行搜索来检测这个类是否已经被加载了。如果两个类的全局限定名是一样的,但是如果命名空间不一样的话,那么它们还是不同的类。不同的命名空间表示class被不同的类装载器装载。
下图展示了类装载器的代理模型。
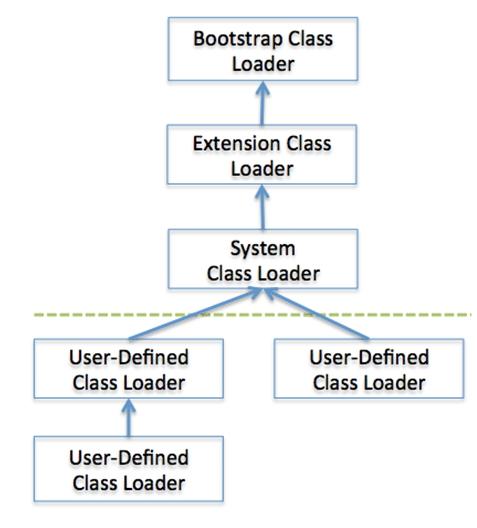
启动类加载器(Bootstrap class loader):这个类装载器是在JVM启动的时候创建的。它负责装载Java API,包含Object对象。和其他的类装载器不同的地方在于这个装载器是通过native code来实现的,而不是用Java代码。
扩展类加载器(Extension class loader):它装载除了基本的Java API以外的扩展类。它也负责装载其他的安全扩展功能。
系统类加载器(System class loader):如果说bootstrap class loader和extension class loader负责加载的是JVM的组件,那么system class loader负责加载的是应用程序类。它负责加载用户在$CLASSPATH里指定的类。
用户自定义类加载器(User-defined class loader):这是应用程序开发者用直接用代码实现的类装载器。
3、类加载的各个阶段
如果类装载器查找到一个没有装载的类,它会按照下图的流程来装载和链接这个类: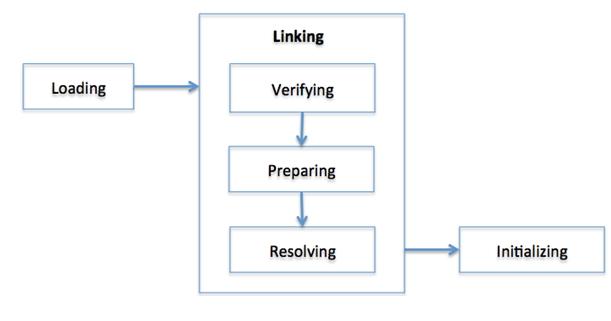
也就是三个阶段: 加载(Loading)、链接(Linking)和初始化(Initializing)
其中 链接(Linking)阶段又分:校验(Verifying)、准备(Preparing)和 解析(Resolving)。
每个阶段的描述如下:
Loading: 类的信息从文件中获取并且载入到JVM的内存里。
Verifying: 检查读入的结构是否符合Java语言规范以及JVM规范的描述。这是类装载中最复杂的过程,并且花费的时间也是最长的。
Preparing: 分配一个结构用来存储类信息,这个结构中包含了类中定义的成员变量,方法和接口的信息。
Resolving: 把这个类的常量池中的所有的符号引用改变成直接引用。
Initializing: 把类中的变量初始化成合适的值。执行静态初始化程序,把静态变量初始化成指定的值。
三、类执行机制
1、执行引擎(Execution Engine)
通过类装载器装载的被分配到JVM的运行时数据区的字节码会被执行引擎执行。
执行引擎以指令为单位读取Java字节码。它就像一个CPU一样,一条一条地执行机器指令。每个字节码指令都由一个1字节的操作码和附加的操作数组成。执行引擎取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过Java字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被JVM执行的语言。字节码可以通过以下两种方式转换成合适的语言。
解释器:一条一条地读取,解释并且执行字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
即时(Just-In-Time)编译器:即时编译器被引入用来弥补解释器的缺点。执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
不过,用JIT编译器来编译代码所花的时间要比用解释器去一条条解释执行花的时间要多。因此,如果代码只被执行一次的话,那么最好还是解释执行而不是编译后再执行。因此,内置了JIT编译器的JVM都会检查方法的执行频率,如果一个方法的执行频率超过一个特定的值的话,那么这个方法就会被编译成本地代码。
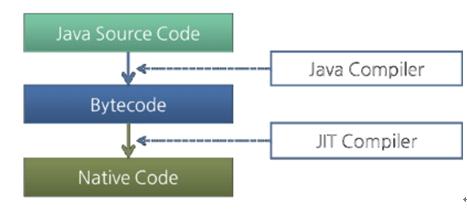
图 :Java编译器和JIT编译器
JVM规范没有定义执行引擎该如何去执行。因此,JVM的提供者通过使用不同的技术以及不同类型的JIT编译器来提高执行引擎的效率。执行方式主要分为解释执行、编译执行、自适应优化执行、硬件芯片执行方式。
第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新的解析一次,Sun JDK采用了token-threading的方式;
第二种,即时解析,也就是装载到内存的字节码,会被JIT(Just-In-Time)编译器在第一次执行时,编译为机器码并缓存,之后就可以重复利用,但是比较耗内存。Oracle JRockit采用的是完全的编译执行。
第三种,自适应优化解析,即将java将使用最频繁的代码编译为优化过的机器码,而使用不频繁的则保持字节码不变,一个自适应的优化器可以使得java虚拟机在80%-90%的时间里执行优化过的本地代码,而只需要执行10%-20%对性能有影响的代码。自适应优化的典型代表是Sun的Hotspot VM。
第四种,一种能够利用本地方法直接解析java字节码的芯片。
Sun JDK在编译上采用了两种模式:Client和Server模式。前者较为轻量级,占用内存较少。后者的优化程序更高,占用内存更多。
大部分的JIT编译器都是按照下图的方式来执行的:
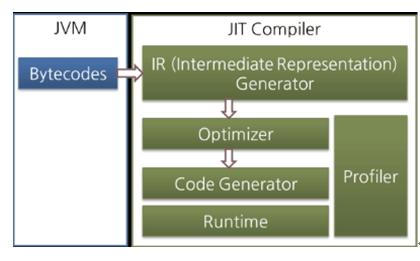
图 : JIT编译器
JIT编译器把字节码转换成一个中间层表达式,一种中间层的表示方式,来进行优化,然后再把这种表示转换成本地代码。
Oracle Hotspot VM使用一种叫做热点编译器的JIT编译器。它之所以被称作”热点“是因为热点编译器通过分析找到最需要编译的“热点”代码,然后把热点代码编译成本地代码。如果已经被编译成本地代码的字节码不再被频繁调用了,换句话说,这个方法不再是热点了,那么Hotspot VM会把编译过的本地代码从cache里移除,并且重新按照解释的方式来执行它。Hotspot VM分为Server VM和Client VM两种,这两种VM使用不同的JIT编译器。
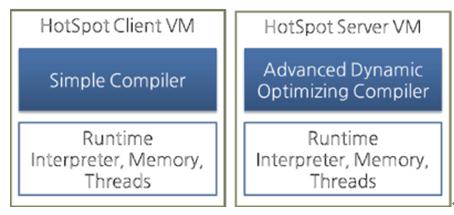
图: Hotspot Client VM and Server VM.
Client VM 和Server VM使用完全相同的运行时,不过如上图所示,它们所使用的JIT编译器是不同的。Server VM用的是更高级的动态优化编译器,这个编译器使用了更加复杂并且更多种类的性能优化技术。
IBM 在IBM JDK 6里不仅引入了JIT编译器,它同时还引入了AOT(Ahead-Of-Time)编译器。它使得多个JVM可以通过共享缓存来共享编译过的本地代码。简而言之,通过AOT编译器编译过的代码可以直接被其他JVM使用。除此之外,IBM JVM通过使用AOT编译器来提前把代码编译器成JXE(Java EXecutable)文件格式来提供一种更加快速的执行方式。
大部分Java程序的性能都是通过提升执行引擎的性能来达到的。正如JIT编译器一样,很多优化的技术都被引入进来使得JVM的性能一直能够得到提升。最原始的JVM和最新的JVM最大的差别之处就是在于执行引擎。
此外,执行引擎也必须保证线程安全性,因而JMM(Java Memory Model)也是由执行引擎确保的。
补充:
Hotspot编译器在1.3版本的时候就被引入到Oracle Hotspot VM里了,JIT编译技术在Anroid 2.2版本的时候被引入到Dalvik VM里。引入一种中间语言,例如字节码,虚拟机执行字节码,并且通过JIT编译器来提升JVM的性能的这种技术以及广泛应用在使用中间语言的编程语言上。例如微软的.Net,CLR(Common Language Runtime 公共语言运行时),也是一种VM,它执行一种被称作CIL(Common Intermediate Language)的字节码。CLR提供了AOT编译器和JIT编译器。因此,用C#或者VB.NET编写的源代码被编译后,编译器会生成CIL并且CIL会执行在有JIT编译器的CLR上。CLR和JVM相似,它也有垃圾回收机制,并且也是基于堆栈运行。
补充:JVM的编译优化技术
编译执行有两种模式:client compiler(-client)和server compiler(-server)
Server compiler又称为C2,较为重量级,C2采用大量传统编译优化技巧,占用内存多,适用于服务器端应用。
“逃逸分析”是C2进行很多优化的基础,逃逸分析是指根据运行状况来判断方法中的变量是否会被外部读取,如不会则认为此变量是逃逸的,基于逃逸分析C2在编译时会做标量替换、栈上分配、同步削除等
1,标量替换:用标量替换聚合量,见代码:
Point point = new Point(1,2);
System.out.println("point.x="+point.x+"; point.y="+point.y);
当point对象在后面的执行过程中未用到时,经过编译后,代码会变成类似下面的结构:
int x = 1;
int y = 2;
System.out.println("point.x="+x+"; point.y="+y);
这种方式的好处是,如果创建的对象并未用到其中的全部变量,则可节省一定的内存,对于代码执行而言,由于无需去找对象的引用,也会更快一些。
2,栈上分配:如果上例中,point是逃逸的,那么C2会选择在栈上直接创建point对象实例,而不是在JVM堆上。
3,同步削除:指同步的对象逃逸,方法外部没有引用到同步的对象,那就没有同步的必要了,C2编译时会直接去掉同步。
Client compiler又称为C1,较轻量级,只做少量性能开销比较高的优化,它占用内存少,适合桌面交互式应用,它的优化方式主要有:方法内联,去虚拟化,冗余削除等。
1,方法内联:在方法中需要调用其它方法,需要经历参数传递、返回值传递及跳转等,方法内联即把调用到的方法的指令直接植入到当前方法中
2,去虚拟化:在装载class之后,进行类层次的分析,如发现接口的方法只提供一个实现类,那么对于调用了此方法的代码,也可以进行方法内联。
3,冗余削除:在编译时,根据运行时状况进行代码折叠或削除。去掉不需要的代码指令。
JVM会根据机器配置来选择C1还是C2,当机器配置CPU达到2核且内存超过2G则选择C2,但是32位windows机器上始终选择C1模式,也可在启动时通过-client或-server来强制指定。
参考资料:http://www.importnew.com/1486.html
2、运行时候的栈结构、方法调用流程
(略)
进一步阅读资料:《深入JVM字节码执行引擎》http://blog.csdn.net/dd864140130/article/details/49515403